This dataset is deprecated. For data on site-level infrastructure, users, and satellite analysis, explore the Frontier Data Centers database.
Our database of over 500 GPU clusters and supercomputers tracks large hardware facilities, including those used for AI training and inference.
This dataset was previously called 'AI Supercomputers' but was renamed to account for its broad coverage of GPU clusters.
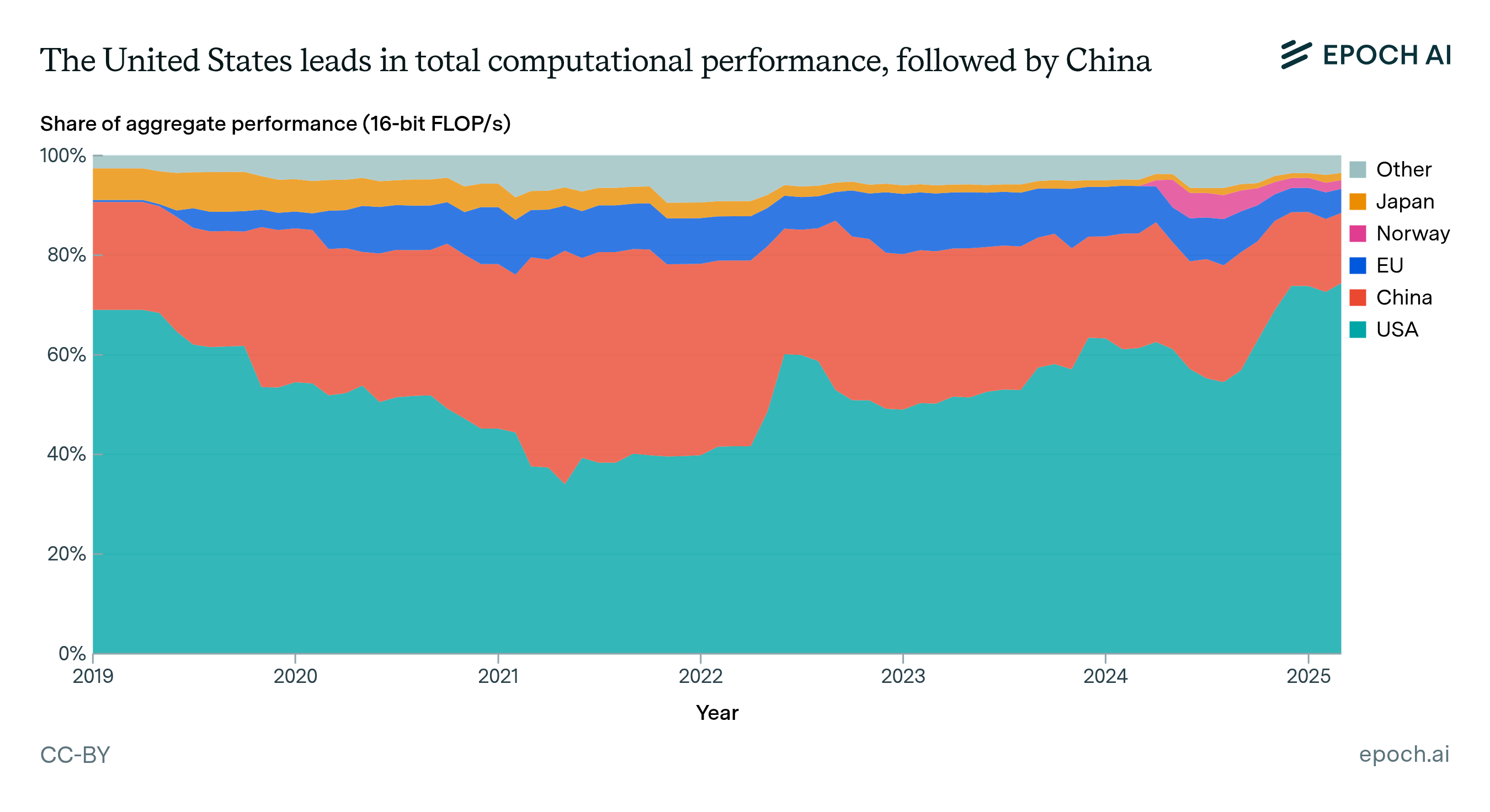
Disclaimer: Our dataset covers an estimated 10–20% of existing global aggregate GPU cluster performance as of March 2025. Planned systems are subject to changes and inherently lower confidence. While coverage varies across companies, sectors, and hardware types due to uneven reporting, we believe the overall distribution remains broadly representative. Future country shares may change dramatically as exponential growth continues. Chinese systems are anonymized and their specifications are rounded.
This dataset tracks GPU clusters, identified from sources including model training reports, news articles, press releases, and web search results. Additional information about our approach to identifying clusters and collecting data about them can be found in the accompanying documentation.
A GPU cluster is a collection of specialized chips, such as GPUs and TPUs, organized to efficiently collaborate and achieve high computational performance. A subset, but not all, of these clusters are used for machine learning and AI workloads.
Many GPU clusters are constructed and used for tasks unrelated to AI, even if the same chips could be used to run AI workloads. In some cases a GPU cluster is built without the networking infrastructure necessary to efficiently support the most demanding AI workloads, or with infrastructure that is extraneous for such workloads.
AI supercomputers are used for training or serving neural network models. Therefore, they typically support number formats favorable for AI training and inference, such as FP16 or INT8, contain compute units optimized for matrix multiplication, have high-bandwidth memory, and rely on AI accelerators rather than CPUs for most of their calculations. A more detailed definition can be found in our documentation and in section 2 of our paper.
We provide the total computational rate of the hardware in the computing cluster, which is the performance of each ML hardware chip times the number of chips.
Historically, government and academic research organizations such as Oak Ridge National Laboratory and Sunway have owned many of the top supercomputers. In recent years, most AI supercomputers are owned by cloud computing providers such as AWS, Google, and Microsoft Azure, or AI laboratories such as Meta and xAI.
The data was primarily collected from machine learning papers, publicly available news articles, press releases, and existing lists of supercomputers.
We created a list of potential supercomputers by using the Google Search API to search key terms like “AI supercomputer” and “GPU cluster” from 2019 to 2025, then used GPT-4o to extract any supercomputers mentioned in the resulting articles. We also added supercomputers from publicly available lists such as Top500 and MLPerf, and GPU rental marketplaces. For each potential cluster, we manually searched for public information such as number and type of chips used, when it was first operational, reported performance, owner, and location. A detailed description of our methods can be found in the documentation and Appendix A of our paper.
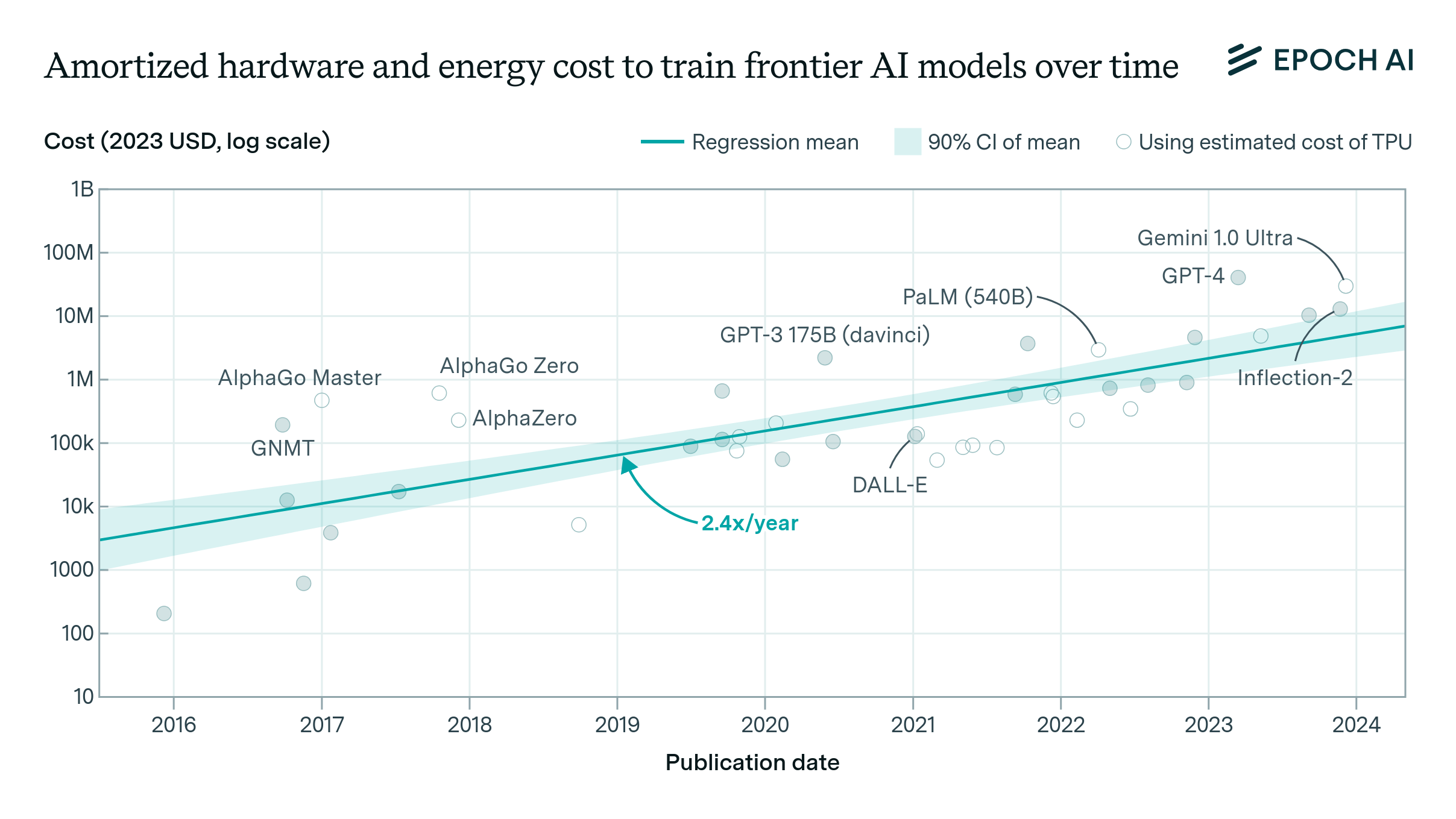
Performance is sometimes reported by the owner of the cluster, or in news reports. Otherwise, it is calculated based on the performance per chip of the hardware used in the cluster, times the number of chips.
Costs are sometimes reported by the owner or sponsor of the cluster. Otherwise, costs are estimated from the cost per chip of the hardware, times the number of chips, multiplied by adjustment factors for intra- and inter-server network hardware.
Power draw is sometimes reported by the owner or operator of the cluster. Otherwise, it is estimated from the power draw per chip, times the number of chips, multiplied by adjustment factors for other hardware and the power usage efficiency of the datacenter.
Detailed methodology definitions can be found in the paper and documentation.
We strive to accurately convey the reported specifications of each cluster. The Status field indicates our assessment of whether the cluster is currently operational, not yet operational, or decommissioned. The Certainty field indicates our assessment of the likelihood that the cluster exists in roughly the form specified in the dataset and the linked sources. If you find mistakes or additional information regarding any clusters in the dataset, please email data@epoch.ai.
We have released a public dataset with a CC-BY license. This public dataset includes all of our data on clusters outside of China and Hong Kong, along with anonymized data on clusters within China, with values rounded to one significant figure and names and links removed. This dataset is free to use, distribute, and reproduce, provided the source and authors are credited under the Creative Commons Attribution license.
Data on Chinese clusters is stored privately to protect the data sources. For inquiries about this data, please contact data@epoch.ai.
Although we strive to maintain an up-to-date database, new GPU clusters are constantly under construction, so there will inevitably be some that have not yet been added. Generally, major clusters should be added within one month of their announcement, and others are added periodically during reviews. If you notice a missing cluster, you can notify us at data@epoch.ai.
Download the data in CSV format.
Explore the data using our interactive tools.
View the data directly in a table format.
Feedback, questions, and comments can be directed to the data team at data@epoch.ai.
Epoch AI’s data is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons Attribution license.
Have a question? Noticed something wrong? Let us know.
Our database of over 500 GPU clusters and supercomputers tracks large hardware facilities, including those used for AI training and inference.