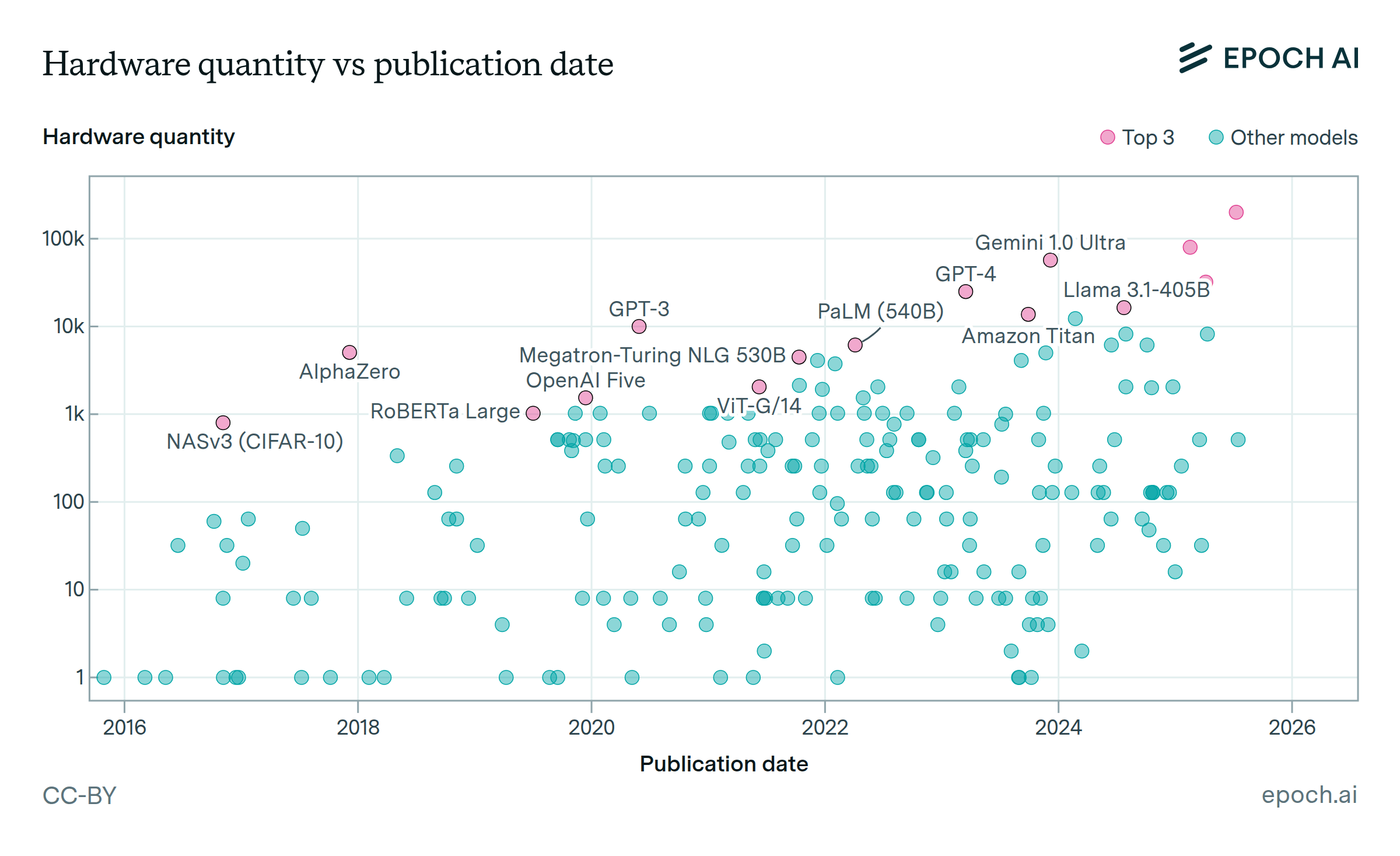
From Google’s NASv3 RL network, trained on 800 GPUs in 2016, to Meta’s Llama 3.1 405B, using 16,384 H100 GPUs in 2024, the number of processors used increased by a factor of over 20. Gemini Ultra was trained with an even larger number of TPUs, but precise details were not reported.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Explore this data

Key data on over 170 AI accelerators, such as graphics processing units (GPUs) and tensor processing units (TPUs).