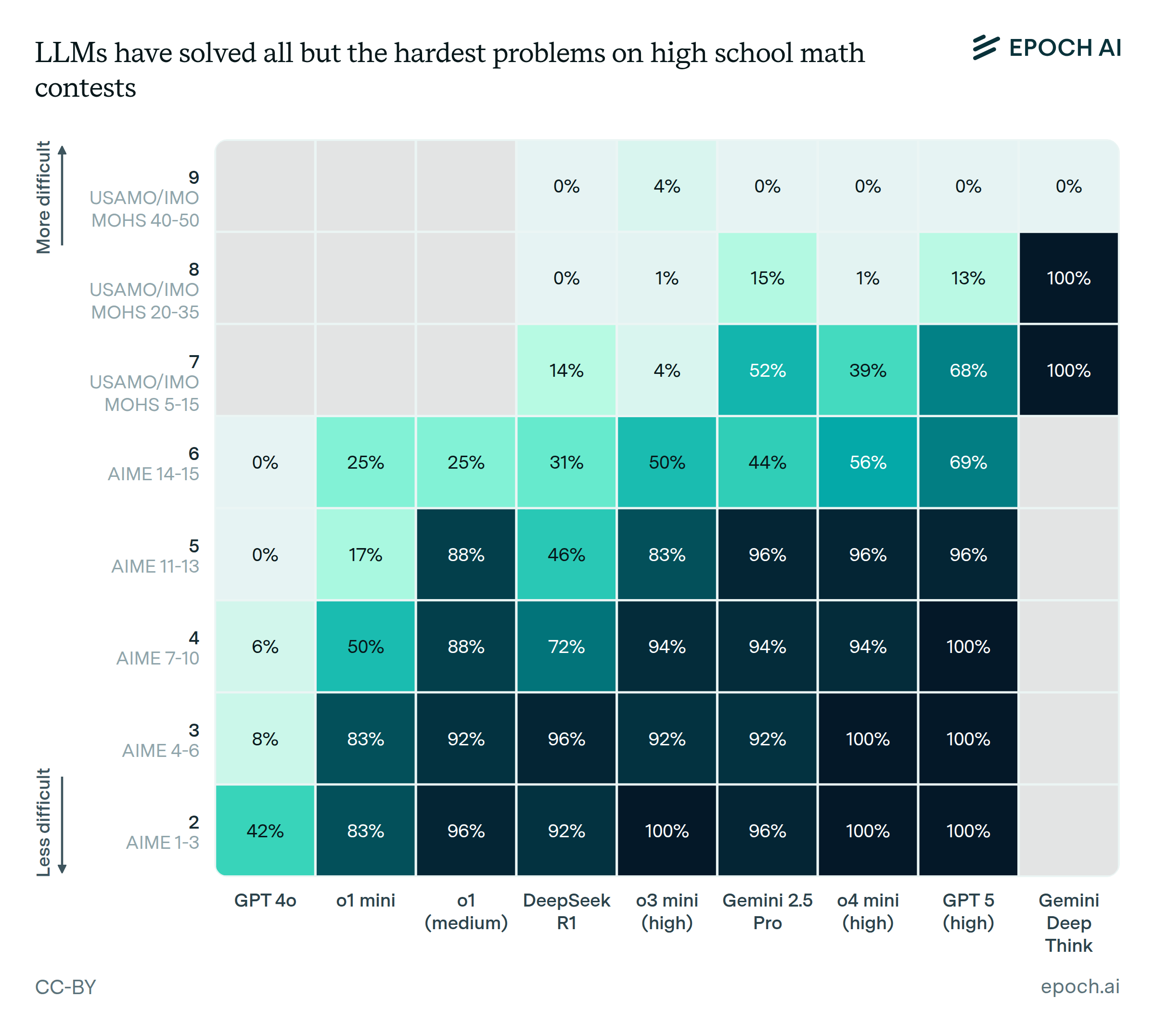
We categorize problems as follows:
| Difficulty Rating | Competition Problems |
|---|
| 2 | AIME 1-3 |
| 3 | AIME 4-6 |
| 4 | AIME 7-10 |
| 5 | AIME 11-13 |
| 6 | AIME 14-15 |
| 7 | USAMO/IMO MOHS 5-15 |
| 8 | USAMO/IMO MOHS 20-35 |
| 9 | USAMO/IMO MOHS 40-50 |
This deviates slightly from the AoPS scale at the lower end: they characterize 2 as “easiest AIME 1-3” and have a special 2.5 rating for “usual AIME 1-3”. We collapse this into the same rating, labeled 2, for ease of interpretation.
We use MOHS ratings to achieve finer-grained classification in the 7, 8, and 9 buckets. This is highly consistent with the AoPS descriptions. For instance, it characterizes “easiest USAMO and IMO 3/6” as 8s, whereas “average USAMO and IMO 3/6” are 9s. We thus group the 10 ratings of the MOHS scale into sets consisting of {5, 10, 15}, {20, 25, 30, 35}, and {40, 45, 50} and assign those overall ratings of 7, 8, and 9.
We omit the 1 and 10 ratings. The former corresponds to “traditional middle/high school word problems” and no actively-evaluated competitions cover this difficulty level. The latter corresponds to “historically hard problems, generally unsuitable for very hard competitions”.
We include models in the main diagram according to whether they score over 5% higher at any difficulty rating, compared to all previously-released models in the dataset. Models are ordered left-to-right by their release date.
We now discuss the degree of saturation at each level.
Difficulty 2-5. These problems pose little remaining challenge: multiple models now score above 95% in each rating.
Difficulty 6. GPT-5’s 69% is the top score at this rating. The gap to 100% reflects a lack of reliability as opposed to a lack of capability: GPT-5 (high) solves each problem at least 1/4 times on MathArena.
The sample size at this rating is small, with only four AIME problems included. To augment this, we also look at a student-organized competition, HMMT, that is also evaluated by MathArena. The AoPS scale rates the more difficult half of HMMT, consisting of 15 problems, as 5.5-6. GPT-5 (high) scored 78% on these, solving all but one problem at least once; other models, including GPT-5-mini (high), solved that one unsolved problem at least once.
Difficulty 7. The situation is similar: not completely saturated, but each of the five problems evaluated by MathArena has been solved at least once. Furthermore, the IMO Gold models all solved the three 7-rated problems on the 2025 IMO in their one-and-only attempt, suggesting that the experimental techniques used by those models can close this reliability gap.
Difficulty 8. The dataset contains four problems with difficulty 8: two each from the 2025 USAMO and 2025 IMO. While MathArena stopped grading 2025 USAMO solutions in June, xAI subsequently reported an internal run of Grok 4 Heavy to have solved the two problems from the USAMO. All of the IMO Gold models solved the two problems on the IMO. Thus, the available data suggests that problems at this rating may be nearly saturated.
Difficulty 9. The dataset contains two problems rated 9, one each from the 2025 USAMO and 2025 IMO. No model has solved either one even once, though there are no publicly available results from the IMO Gold models on the USAMO problems.
To augment this small sample, we test the publicly available version of Deep Think on the two easy-to-check problems from the 2024 IMO: P5 which is rated 8, and P6 which is rated 9. This version of Deep Think is “a variation” of the IMO Gold model, though Google reports that it does somewhat worse on the IMO problems (61% vs. 83%). We thus sample it 10 times for each problem to compensate for this lower baseline performance. It does not solve either problem in any sample.
On the 2025 USAMO problem rated a 9, MathArena awarded o3-mini (high) 0.5 points of partial credit, out of a total of 7. This corresponded to a largely incomplete solution which started in generally the right direction. We don’t consider this to be meaningful progress toward solving the problem.