The training compute of top Chinese language models grew rapidly after 2019, catching up to the top models globally by late 2021. Since then, China’s rate of scaling has fallen behind. The top 10 Chinese language models by training compute have scaled up by about 3x per year since late 2021, which is slower than the 5x per year trend maintained elsewhere since 2018. At China’s current rate, it would take about two years to reach where the global top models are today.
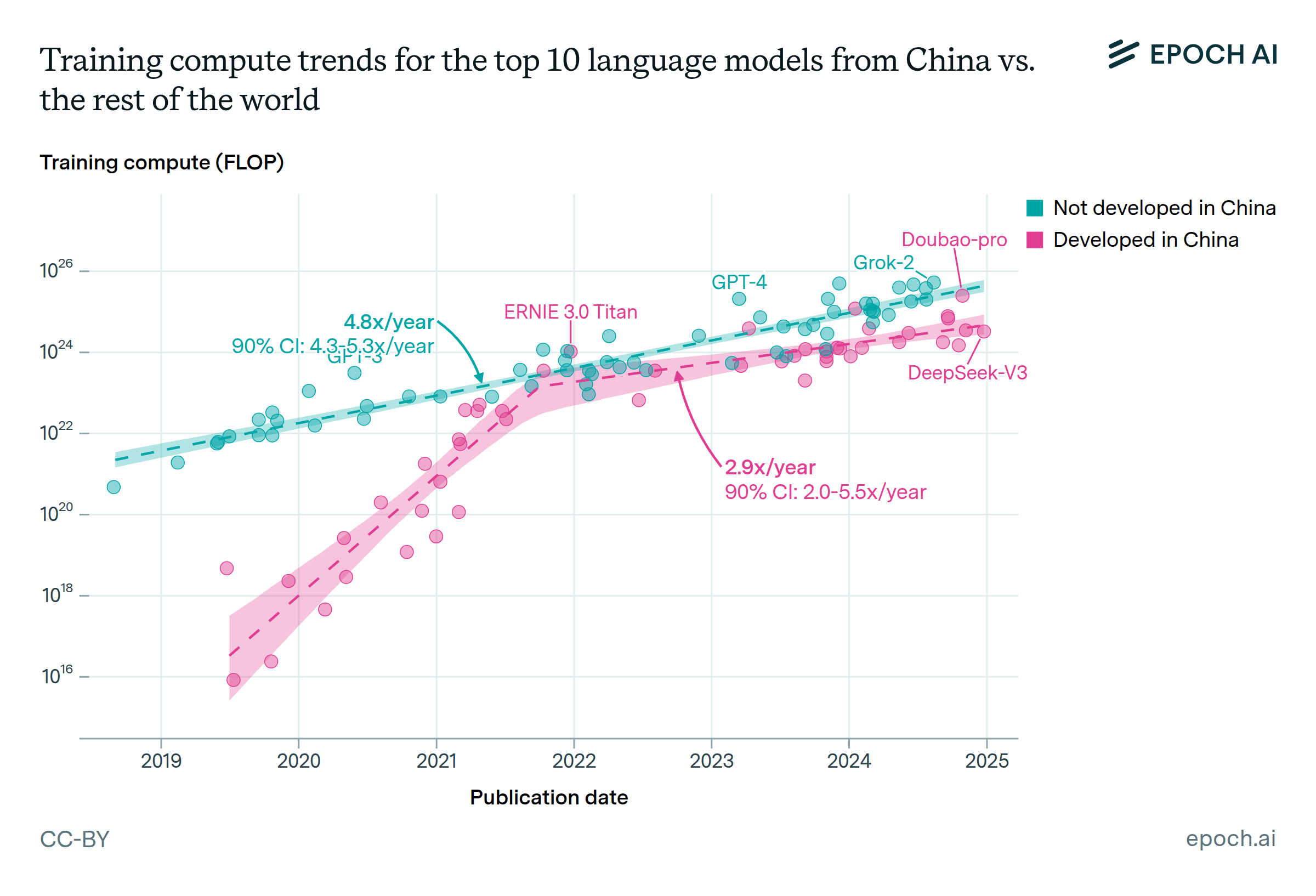
The difference looks less dramatic when comparing just the largest known models from each region. Grok-2, the largest known US model, used twice the training compute of China’s largest known model Doubao-pro, released 3 months later. Given China’s current scaling rate of 3x per year, it would take 8 months to scale from Doubao-pro to Grok-2’s level of compute.
Epoch's work is free to use, distribute, and reproduce provided the source and authors are credited under the Creative Commons BY license.
Learn more about this graph
We labeled models in our database of AI models as “Developed in China” if at least one of the organizations developing the model was headquartered inside the People’s Republic of China, and “Not developed in China” otherwise. The “Developed in China” and “Not developed in China” sets of models were each narrowed down to the rolling top 10 by training compute, to focus on the frontier of scaling in each region. We then filtered to models in the Language or Multimodal domain, and to models released since 2018, to focus on “LLMs” as they are typically understood. The trendlines in the figure are the best overall fit after searching over breakpoints in a two-segment, log-linear regression model.
Data
Analysis
Explore this data
Our comprehensive database of over 3200 models tracks key factors driving machine learning progress.